#导入需要的包
import numpy as np
import torch
from torch import nn
from PIL import Image
import torchvision
import matplotlib.pyplot as plt
import os
from torchvision import datasets, transforms,utils
Step1:准备数据。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])])
train_data = datasets.MNIST(root = "./data/",
transform=transform,
train = True,
download = True)
test_data = datasets.MNIST(root="./data/",
transform = transform,
train = False)
print(len(train_data))
print(len(test_data))
60000
10000
train_data 的个数:60000个训练样本
test_data 的个数:10000个训练样本
train_loader = torch.utils.data.DataLoader(train_data,batch_size=128,
shuffle=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=128,
shuffle=True,num_workers=2)
print(len(train_loader))
print(len(test_loader))
469
79
加载到dataloader中后,一个dataloader是一个batch的数据
data_iter = iter(train_loader)
print(next(data_iter))
[tensor([[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]],
[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]],
[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]],
...,
[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]],
[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]],
[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]]]), tensor([3, 4, 3, 0, 4, 3, 1, 4, 4, 7, 0, 4, 5, 3, 4, 0, 1, 3, 7, 4, 7, 7, 7, 6,
4, 9, 1, 8, 7, 5, 3, 9, 1, 8, 5, 6, 4, 6, 0, 4, 3, 7, 2, 5, 8, 0, 8, 6,
6, 6, 0, 4, 6, 9, 0, 0, 1, 4, 6, 8, 7, 6, 1, 9, 5, 0, 1, 5, 2, 7, 9, 6,
6, 9, 6, 6, 5, 5, 1, 4, 8, 9, 3, 9, 4, 4, 0, 2, 0, 0, 9, 2, 0, 2, 0, 3,
4, 5, 7, 1, 0, 2, 8, 6, 8, 3, 8, 4, 6, 3, 0, 1, 1, 5, 7, 3, 3, 7, 6, 7,
8, 2, 0, 7, 8, 7, 4, 4])]
从二维数组生成一张图片
oneimg,label = train_data[0]
oneimg = oneimg.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
oneimg = oneimg * std + mean
oneimg.resize(28,28)
plt.imshow(oneimg)
plt.show()

从三维生成一张黑白图片
oneimg,label = train_data[0]
grid = utils.make_grid(oneimg)
grid = grid.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
grid = grid * std + mean
plt.imshow(grid)
plt.show()
plt.savefig("test.jpg")
<Figure size 432x288 with 0 Axes>
输出一个batch的图片和标签
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# torchvision.utils.make_grid 将图片进行拼接
imshow(torchvision.utils.make_grid(iter(train_loader).next()[0]))

Step2.网络配置
网络结构是两个卷积层,3个全连接层。
Conv2d参数
- in_channels(int) – 输入信号的通道数目
- out_channels(int) – 卷积产生的通道数目
- kerner_size(int or tuple) - 卷积核的尺寸
- stride(int or tuple, optional) - 卷积步长
- padding(int or tuple, optional) - 输入的每一条边补充0的层数
1.定义一个CNN网络
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Conv2d(1,32,kernel_size=3,stride=1,padding=1)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1)
self.fc1 = nn.Linear(64*7*7,1024)#两个池化,所以是7*7而不是14*14
self.fc2 = nn.Linear(1024,512)
self.fc3 = nn.Linear(512,10)
# self.dp = nn.Dropout(p=0.5)
def forward(self,x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 7* 7)#将数据平整为一维的
x = F.relu(self.fc1(x))
# x = self.fc3(x)
# self.dp(x)
x = F.relu(self.fc2(x))
x = self.fc3(x)
# x = F.log_softmax(x,dim=1) NLLLoss()才需要,交叉熵不需要
return x
net = CNN()
2.定义损失函数和优化函数
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
#也可以选择Adam优化方法
# optimizer = torch.optim.Adam(net.parameters(),lr=1e-2)
Step3.模型训练
train_accs = []
train_loss = []
test_accs = []
# 使用GPU训练模型
device = torch.device("cuda:0")
net = net.to(device)
for epoch in range(40):
running_loss = 0.0
for i,data in enumerate(train_loader,0):#0是下标起始位置默认为0
# data 的格式[[inputs, labels]]
# inputs,labels = data
inputs,labels = data[0].to(device), data[1].to(device)
#初始为0,清除上个batch的梯度信息
optimizer.zero_grad()
#前向+后向+优化
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
# loss 的输出,每个一百个batch输出,平均的loss
running_loss += loss.item()
if i%100 == 99:
print('[%d,%5d] loss :%.3f' %
(epoch+1,i+1,running_loss/100))
running_loss = 0.0
train_loss.append(loss.item())
# 训练曲线的绘制 一个batch中的准确率
correct = 0
total = 0
_, predicted = torch.max(outputs.data, 1)
total = labels.size(0)# labels 的长度
correct = (predicted == labels).sum().item() # 预测正确的数目
train_accs.append(100*correct/total)
print('Finished Training')
[1, 100] loss :2.294
[1, 200] loss :2.269
[1, 300] loss :2.221
[1, 400] loss :2.088
[2, 100] loss :1.078
[2, 200] loss :0.631
[2, 300] loss :0.483
[2, 400] loss :0.402
[3, 100] loss :0.331
[3, 200] loss :0.297
[3, 300] loss :0.265
[3, 400] loss :0.247
[4, 100] loss :0.225
[4, 200] loss :0.205
[4, 300] loss :0.200
[4, 400] loss :0.176
[5, 100] loss :0.154
[5, 200] loss :0.163
[5, 300] loss :0.151
[5, 400] loss :0.148
[6, 100] loss :0.133
[6, 200] loss :0.119
[6, 300] loss :0.123
[6, 400] loss :0.114
[7, 100] loss :0.110
[7, 200] loss :0.103
[7, 300] loss :0.103
[7, 400] loss :0.097
[8, 100] loss :0.091
[8, 200] loss :0.097
[8, 300] loss :0.092
[8, 400] loss :0.088
[9, 100] loss :0.090
[9, 200] loss :0.086
[9, 300] loss :0.073
[9, 400] loss :0.077
[10, 100] loss :0.079
[10, 200] loss :0.074
[10, 300] loss :0.064
[10, 400] loss :0.078
[11, 100] loss :0.065
[11, 200] loss :0.074
[11, 300] loss :0.071
[11, 400] loss :0.069
[12, 100] loss :0.064
[12, 200] loss :0.059
[12, 300] loss :0.070
[12, 400] loss :0.064
[13, 100] loss :0.055
[13, 200] loss :0.062
[13, 300] loss :0.062
[13, 400] loss :0.063
[14, 100] loss :0.058
[14, 200] loss :0.058
[14, 300] loss :0.064
[14, 400] loss :0.053
[15, 100] loss :0.055
[15, 200] loss :0.054
[15, 300] loss :0.051
[15, 400] loss :0.054
[16, 100] loss :0.052
[16, 200] loss :0.053
[16, 300] loss :0.048
[16, 400] loss :0.052
[17, 100] loss :0.053
[17, 200] loss :0.045
[17, 300] loss :0.051
[17, 400] loss :0.050
[18, 100] loss :0.046
[18, 200] loss :0.042
[18, 300] loss :0.050
[18, 400] loss :0.049
[19, 100] loss :0.048
[19, 200] loss :0.045
[19, 300] loss :0.048
[19, 400] loss :0.043
[20, 100] loss :0.042
[20, 200] loss :0.045
[20, 300] loss :0.040
[20, 400] loss :0.043
[21, 100] loss :0.039
[21, 200] loss :0.042
[21, 300] loss :0.040
[21, 400] loss :0.043
[22, 100] loss :0.039
[22, 200] loss :0.039
[22, 300] loss :0.040
[22, 400] loss :0.039
[23, 100] loss :0.040
[23, 200] loss :0.040
[23, 300] loss :0.035
[23, 400] loss :0.037
[24, 100] loss :0.036
[24, 200] loss :0.038
[24, 300] loss :0.036
[24, 400] loss :0.037
[25, 100] loss :0.038
[25, 200] loss :0.035
[25, 300] loss :0.036
[25, 400] loss :0.036
[26, 100] loss :0.034
[26, 200] loss :0.033
[26, 300] loss :0.036
[26, 400] loss :0.035
[27, 100] loss :0.029
[27, 200] loss :0.031
[27, 300] loss :0.032
[27, 400] loss :0.038
[28, 100] loss :0.028
[28, 200] loss :0.031
[28, 300] loss :0.033
[28, 400] loss :0.032
[29, 100] loss :0.033
[29, 200] loss :0.030
[29, 300] loss :0.026
[29, 400] loss :0.030
[30, 100] loss :0.031
[30, 200] loss :0.030
[30, 300] loss :0.030
[30, 400] loss :0.028
[31, 100] loss :0.032
[31, 200] loss :0.030
[31, 300] loss :0.024
[31, 400] loss :0.030
[32, 100] loss :0.030
[32, 200] loss :0.027
[32, 300] loss :0.028
[32, 400] loss :0.027
[33, 100] loss :0.027
[33, 200] loss :0.028
[33, 300] loss :0.027
[33, 400] loss :0.027
[34, 100] loss :0.025
[34, 200] loss :0.027
[34, 300] loss :0.027
[34, 400] loss :0.027
[35, 100] loss :0.021
[35, 200] loss :0.026
[35, 300] loss :0.026
[35, 400] loss :0.026
[36, 100] loss :0.029
[36, 200] loss :0.024
[36, 300] loss :0.023
[36, 400] loss :0.021
[37, 100] loss :0.023
[37, 200] loss :0.023
[37, 300] loss :0.026
[37, 400] loss :0.023
[38, 100] loss :0.025
[38, 200] loss :0.020
[38, 300] loss :0.025
[38, 400] loss :0.022
[39, 100] loss :0.025
[39, 200] loss :0.022
[39, 300] loss :0.024
[39, 400] loss :0.020
[40, 100] loss :0.022
[40, 200] loss :0.020
[40, 300] loss :0.021
[40, 400] loss :0.023
Finished Training
模型的保存
PATH = './mnist_net.pth'
torch.save(net.state_dict(), PATH)
Step4.模型评估
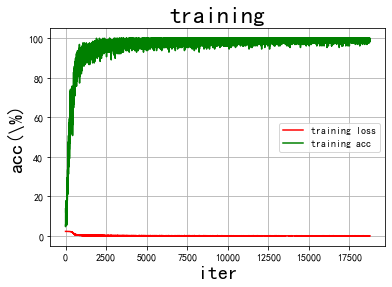
画图
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("acc(\%)", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
train_iters = range(len(train_accs))
draw_train_process('training',train_iters,train_loss,train_accs,'training loss','training acc')
检验一个batch的分类情况
dataiter = iter(test_loader)
images, labels = dataiter.next()
# print images
test_img = utils.make_grid(images)
test_img = test_img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
test_img = test_img*std+0.5
plt.imshow(test_img)
plt.show()
print('GroundTruth: ', ' '.join('%d' % labels[j] for j in range(64)))

GroundTruth: 0 1 2 1 4 1 2 0 7 2 9 0 2 9 1 5 8 7 5 1 8 3 6 4 7 7 2 3 4 9 5 1 3 7 4 0 2 6 1 4 1 6 0 4 1 9 5 4 1 5 7 7 8 7 5 4 5 8 8 3 1 5 5 9
测试集上面整体的准确率
correct = 0
total = 0
with torch.no_grad():# 进行评测的时候网络不更新梯度
for data in test_loader:
images, labels = data
outputs = test_net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)# labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
Accuracy of the network on the test images: 98.860000 %
10个类别的准确率
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = test_net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels)
# print(predicted == labels)
for i in range(10):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %d : %4f %%' % (
i, 100 * class_correct[i] / class_total[i]))
Accuracy of 0 : 100.000000 %
Accuracy of 1 : 100.000000 %
Accuracy of 2 : 100.000000 %
Accuracy of 3 : 100.000000 %
Accuracy of 4 : 98.630137 %
Accuracy of 5 : 98.765432 %
Accuracy of 6 : 97.530864 %
Accuracy of 7 : 97.402597 %
Accuracy of 8 : 97.058824 %
Accuracy of 9 : 98.750000 %